Optimizing AI and Deep Learning Performance
by Sven Breuner –
As AI and deep learning uses skyrocket, organizations are finding they are running these systems on similar resource as they do with high-performance computing (HPC) systems – and wondering if this is the path to peak efficiency.
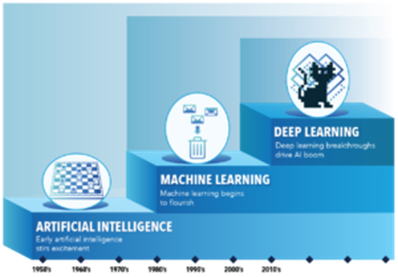
Figure 1. Evolution of AI, ML and DL
Ostensibly AI and HPC architectures have a lot in common, as AI has evolved into even more data-intensive machine learning (ML) and deep learning (DL) domains (Figure 1). Workloads often require multiple GPU systems as a cluster, and share those systems in a coordinated way among multiple data scientists. Secondly, both AI and HPC workloads require shared access to data at a high level of performance and communicate over a fast RDMA-enabled network. Especially in scientific research, the classic HPC systems nowadays tend to have GPUs added to the compute nodes to have the same cluster suitable for classic HPC and new AI/DL workloads.
Yet AI and DL are different from HPC, their applications needs are different, and the deep learning process in particular (Figure 2) has requirements that simply buying more GPU servers won’t fix.
Three Critical Phases in Deep Learning
Phase 1: Data Preparation – Extract, Transform, Load (ETL)
Often data arrives in a format that is not suitable for training – perhaps the resolution or the position of relevant objects inside an image is off. In the Extract, Transform, and Load (ETL) step, systems prepare the dataset in a normalized format that is suitable for training. What makes the best format for training is not always obvious from the beginning and can change over time, so data scientists often try different variations. The speed of the GPU and storage systems here makes the difference for whether the data scientist can go home for the rest of the day or only go for a coffee and then continue working when trying a new variation.
Phase 2: Training
“Teaching” computers to recognize a target item, such as learning to “see” a dog by learning what makes for “doggyness,” is surprisingly complex and data-intensive. The GPU systems doing the “seeing “ need to process hundreds of thousands of dogs in different colors, angles, poses and sizes. Then the entire dataset is often processed repeated in a different order, image rotation factor, stretched, or in other variations, to improve the accuracy of the recognition. As data scientists improve model generation based on the existing training, what ensues is an endless process running continuously. This is phase represents one of the most demanding workloads that exist for storage systems today and is very different from the traditional HPC-style rather large file streaming oriented access pattern. This also explains the challenge in finding appropriate storage solutions that meet their small file performance demand without costing more than the compute systems by which they are used.
Phase 3: Inference
Lastly during the inference phase, systems put the trained model to the test by letting the computer recognize whatever objects it has been trained on. Object recognition typically happens in real-time – for example, in security systems trained to recognize persons, there will be a continuous live video feed from cameras that needs to be analyzed. The goal is to go beyond recognizing an image is a person, to identifying if a certain person of interest from a database is the one before the camera in real-time. This means the latency of data access becomes a critical factor to keep up with the live feed.
Architecting DL Training for Better Performance
The closer look at each phase above shows that the storage system can be a limiting factor. Addressing this first requires a fast data path to the storage. RDMA-based network transports RoCE (RDMA over Converged Ethernet) and InfiniBand have become the standards for maintaining efficiency and low access latency even during highly concurrent access for the GPUs.
Software-defined storage can be impactful in enabling greater performance especially in the training phase of DL where low latency and high read operations per second are required. NVMe Flash has become the de facto technology standard in such applications, since it provides low latency and high IOPS at a much better price per performance ratio compared to classic spinning disks. The critical issue that remains, however, is how to architect the data center so as to deliver these high IOPS at low latency from the storage servers to the GPU nodes.
Example: DL Training in Commercial Applications
Early movers have demonstrated several options for boosting AI and DL performance through next-generation storage approaches that turn multiple standard NVMe servers into a logical shared pool which can be made available anywhere on the network. (Figure 3.) Such virtualization of on-premise storage resources and making them accessible anywhere on the network is similar to the functionality of elastic, persistent storage in the public cloud.
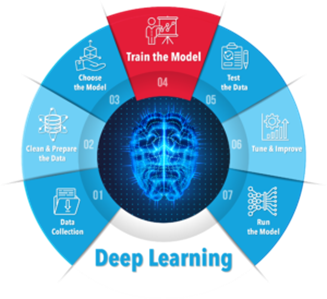
Figure 2. Deep Leaning Phase 2: Training the Model
For example, a Midwest-based technology provider to the automotive and insurance-related industries has deployed the world’s first in-production AI solution for estimating complex automotive-related insurance claims. Its estimating logic and AI capabilities can pre-populate an estimate with suggestions for human estimators to review, edit, and advance.
Training the model in the company’s estimating workflow included a series of AI-based solutions that required a computing infrastructure with massive scalability. Beyond using GPU servers and high-speed networking infrastructure, the company needed to go beyond traditional storage options in order to deliver the high throughput and low latency the workflow required. The task of processing massive volumes of small files per second containing text and images demands both low latency and high throughput – and is far more challenging than typical HPC storage workloads with lesser volumes of massive files.
Using a scale-out, software-defined storage solution along with the parallel file system, the company obtained three to four times faster analysis of data sets. The company’s storage throughput is now 10 to 15 times greater, and latency is negligible.
Example: DL in Scientific Research
The Science and Technology Facilities Council (STFC) supports pioneering scientific and engineering research by over 1,700 academic researchers worldwide on space, environmental, materials and life sciences, nuclear physics, and much more. When data scientists at STFC are training machine learning models, they literally process hundreds of terabytes of data and they need to do so in the shortest amount of time. STFC’s Scientific Machine Learning (SciML) Group often utilize deep neural networks running on state of the art GPU computing systems to expedite analyses. GPUs have amazing performance, processing up to 16GB of data per second, yet often the local NVMe resources are not optimized for efficiency and are much too limited in capacity.
By using an elastic NVMe approach to scale-out storage, STFC obtained an average latency of only 70 microseconds – nearly one‐quarter of the typical 250 microsecond latency of traditional controller‐based enterprise storage when running NVIDIA validation tests on each NVIDIA DGX‐2 system. In doing so, it reduced machine learning training time three-to-four days to under an hour.
Example: DL in AI as a Service
InstaDeep offers an AI as a Service solution that puts AI workloads in reach of a wider range of organizations that may not have the needs or means to run their own AI stack.
Of its handful of essential requirements including modular scalability and flexibility for various kinds of workloads, efficiency where GPUs delivered the highest ROI was key to InstaDeep’s business. As soon as it deployed its first GPU system, the InstaDeep infrastructure team learned that although the GPUs had massive network connectivity, their 4TB of local storage was far less than the 10s to 100s of terabytes (TBs) required by customer workloads. The InstaDeep team investigated external storage options and noticed that with traditional arrays they would get much more capacity but the performance ultimately would hinder AI workloads, since applications needed to move data to and from the GPU systems, interrupting the workflow and impacting system efficiency.
By using an elastic NVMe software as an abstraction layer between the GPUs and the SSDs, InstaDeep could access the full low-latency and high IOPs/BW benefits of NVMe in a distributed and linearly scalable architecture.
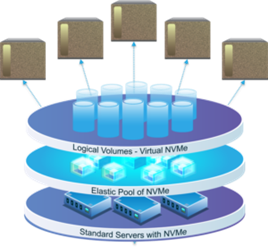
Figure 3. Storage architecture using a logical shared pool of NVMe resources.
Key Takeaways for Accelerating AI/Deep Learning Performance
The experience of these organizations and others suggest four key strategies for optimizing AI and Deep Learning data center performance.
- Clustering multiple GPU systems can allow greater efficiency. While clustering almost comes natural for people with a HPC background, today’s GPU reference designs emphasize scale out capabilities with up to 16 GPUs in a single server. Having multiple GPUs inside a single server enables efficient data sharing and communication inside the system, as well as cost-effectiveness by avoiding the cost overhead of multiple servers. However, more GPUs in a single server also means that the single server becomes more demanding of networking and storage resources. Thus, such a multi-GPU server needs to be prepared to read incoming data at a very high rate to keep the GPUs busy, meaning it needs an ultra-high-speed network connection all the way through to the storage system for the training database. However, at some point a single server will no longer be enough to work through the grown training database in reasonable time, so building a shared storage infrastructure into the design will make it easier to add GPU servers as AI/ML/DL use expands.
- Deploy resource scheduling approaches, including Kubernetes. No matter whether the hardware design decision was to scale up or to scale out, infrastructure needs to be able to deal with resource sharing and thus all phases of the AI workflow at the same time. Kubernetes has become a popular solution for resource sharing by making cloud technology available on premises. With effective resource scheduling, when one group of data scientists get new data that needs to be ingested and prepared, others will train on their available data, while elsewhere, previously generated models will be used in production – all seamlessly at the same time without any conflicts or the infamous need to ask a colleague “Are you finally done now, so that I can start working with the system?”
- Elasticity matters almost as much as raw IOPs. Most AI storage initiatives focus on achieving high read throughput and low latency, which is certainly required. However capacity and performance need elasticity in more than just storage. Capacity elasticity to accommodate any size or type of drive, so that as flash media evolve and flash drive characteristics expand, data centers can maximize performance/$ at scale, when it matters the most. Also supporting performance elasticity is key. Since AI data sets need to grow over time to further improve the accuracy models, each incremental storage addition should deliver the equivalent incremental performance. This allows organizations to start small and grow non-disruptively.
- Connecting it all together. With very demanding GPUs (and data scientists) on the one end and very capable NVMe storage on the other end, the remaining aspect that requires attention is the network to connect everything. Customers trying to retrofit AI into their existing datacenter will often notice that their classic network infrastructure is inappropriate to transfer data at a rate and latency that is required to feed the planned number of GPUs. Network administrators will probably appreciate this as the perfect opportunity to get the budget approved for a significant upgrade of the network backbone, from which in turn other applications on the network might benefit as well.
Data center optimization technology is an exciting domain with key elements that are readily available, robust and proven today, and lots more debuting every quarter. Organizations starting with AI/ML/DL today have a tremendous advantage compared to deployments rolled out just a few years ago. The only challenge is to pick the right hardware and tools for the job – and find the most knowledgeable resources for help.
Category: Uncategorized






