Big Data and the Brain: Keeping the Cognitive Load in Check
 Having a large amount of data is not useful by itself, it has to be easy to find and retrieve the data for later use. Part of what makes this challenging is the human brain. In this post, we will review how the limits of the brain have helped to shape the file systems we use and explains, in part, the differences between block, object and file storage from a user’s perspective.
Having a large amount of data is not useful by itself, it has to be easy to find and retrieve the data for later use. Part of what makes this challenging is the human brain. In this post, we will review how the limits of the brain have helped to shape the file systems we use and explains, in part, the differences between block, object and file storage from a user’s perspective.
Limits of the Brain: Chunking and Categorization
While technology like a Hyperfiler can address exabytes of data and scale linearly to petabytes, a human cannot grasp that data when presented as a pile of bytes. Related to computer technology, the cognitive mechanism to keep the data volume under control has been understood only recently in the 50s, namely in the groundbreaking paper by G.A. Miller – “The magical number seven, plus or minus two: Some limits on our capacity for processing information.”
Of course, the principle has been known for thousands of years and is described in antique cosmologies, but Miller’s paper came out when computers were being introduced to non-specialists and it was necessary to teach computers to smile—timing is everything. Today, software engineers may no longer be aware of Miller’s paper, but the basic principles of human-computer interface design as well as those for data visualization, have their origins in this paper.
Miller is interested in our working memory; how many chunks of information we humans can process directly at any given time. You can think of it as the number of CPU registers in our brain, when viewed as a computer. It turns out that our immediate memory can hold only 7 ± 2 chunks of information. This means that we have to break down information into categories each holding 7 ± 2 chunks. This is the powerful method we humans use to process huge amounts of information with relatively small brains.
When we compound information, at each aggregation step we have to recode the data so that the number of chunks does not grow beyond 7 ± 2. In cognitive science, this process is called categorization: as soon we have more than 7 ± 2 items of anything, we give them a new name and treat them as a new unit.
The number 7 ± 2 is not strict. When we have an enumeration and there is a rule to derive the chunks, we can have more than 9. For example, we have 7 days and call them a week, but we have no problem with a month of 30 days because we just number them 1, 2, 3, … 30. Sometimes there are natural constraints that force us to consider categories with more chunks, in which case we have to bite the bullet and increase the cognitive load, but in computer science we try to avoid that. Examples of larger categories are the months in a year and the number of basic color terms: in both cases there are 12 chunks.
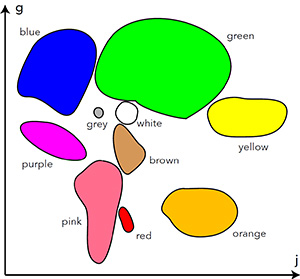 The basic color terms represented in a perceptually uniform color space. The abscissa is correlated to the amount of yellowness and the ordinate to the amount of blueness. Note that this is not a tiling: there is a large uncategorized area. The various categories have very different areas and shapes
The basic color terms represented in a perceptually uniform color space. The abscissa is correlated to the amount of yellowness and the ordinate to the amount of blueness. Note that this is not a tiling: there is a large uncategorized area. The various categories have very different areas and shapes
Applying Categorization to Local File Systems
The same happened with storage. In the early days, we used to run one job at the time and it had an input file, a master file to be updated, and an output file. The drum drives for non-volatile storage were relatively small and held few files, so we could keep a table on a blackboard in the datacenter with the tracks and block assigned to each file. When the Winchester disk was invented, the capacity rose very rapidly and disks started holding thousands of files.
For humans, the cognitive load problem at first was solved by using rules to label the chunks, for example a project acronym followed by a consecutive number. However, computers had a hard time finding the location of files. The blackboard as a file directory was no longer viable and had to be stored digitally on the disk as a special file called file directory, typically a table (array). To find the location of a file, the operating system had to scan the array until it got a name match, which in the worst case for n files took in the order of n IOs. This was too slow and it became common to store the directory in a balanced tree instead of an array, because in the worst case the operating system can find the file in the order of log n IOs. The B-tree, invented for this purpose in 1972 by Rolf Bayer and Ed McCreight at Boeing, is a popular data structure for a file directory.
With the proliferation of applications and files it became clear that also for humans, using rules to create file names was not ergonomic. The concept of folders or directories was invented. When there are too many files in a folder, we recode the files by introducing a new nesting level and re-categorizing the files. This leads to hierarchical file systems structured as trees of directories and files.
There are data structures where the directory tree reflects the categorization of the files, like Ed Fredkin’s trie. The trie is well known as the data structure for storing a predictive text or autocomplete dictionary.
Smalltalk programmers had the same categorization problem with their classes & methods and invented the columnar class browser. This user interface, based on the recoding paradigm, is so powerful, that it still widely used both in programming tools and for file browsers, as shown in this figure:
The columnar file browser is a direct descendant of the Smalltalk class browser.
Although there are many options for implementing a file directory, they are transparent to the user, because they implement the POSIX (Portable Operating System Interface) API for accessing the file system. Application programs are written for this API and do not need any special provisions for the file system.
Applying Categorization to Storage Systems
So far, the storage has been the local drive attached to the workstation or server. The situation is different in the case of a storage system.
Many commercial applications are transaction-based. The data is highly structured and it must be possible to find and update a record as efficiently as possible. A relational database is an organized collection of data that is stored in normalized tables. Queries are supported by indices particular to each database and its usage patterns. To minimize IO, queries are run on the server to avoid copying tables to the client; elaborated caching schemes further reduce drive IO. To allow concurrent access, complex locking mechanisms must be designed, with the constraint of resolving deadlocks. Last but not least, it must be possible to instantaneously recover a database in case of a failure.
A block storage system abstracts the capabilities of the underlying storage media through a simple, yet general interface to various types of devices like hard drives, flash devices and so on. File systems rely on block storage as their underpinning. Block-oriented interfaces can also be exposed directly.
On a workstation or server, it would be too inefficient to store database tables as individual files. Instead, the entire database is stored in few files, which the database implements over block storage.
In a way, the opposite of a transaction occurs when data is stored once and for all without ever being modified. Also, the data may be accessed only a few times and never be organized in any way. A typical example is modern photography: the majority of people are just interested in the act of taking a photograph, not in sharing or viewing the resulting image in a story. Therefore, we may speculate that the only time an image is viewed might be when it is shared on a social network.
In this type of photography, we do not need to categorize the images and we do not need to be able to retrieve them later. The size is known before the image is stored. All that is needed from a storage system is the ability to store the object and get back an address or URL. Usually the address is computed from a hash function so the objects are distributed evenly in the storage system. When more storage capacity is needed, just the hash function changes when drives are added. Since the data is read-only, no locking is necessary.
In this situation where data is created, read a few times, then never accessed again by humans, just by data mining programs, a file system is not necessary and we have an object storage system. The difference to the block storage system is that it must have a facility to store and manage the metadata for each object.
Distributed File Systems Are Different Altogether
In summary, a storage system for databases can be block storage and a storage system for (large) immutable objects can be object storage. All other applications are written assuming POSIX-style file system semantics, so we would like to have a file based storage system when we emancipate from local storage. However, this turns out to be very difficult.
On a local file system, the directories are placed on the same storage device where the data is stored. In a well-designed distributed storage system, the collection of directories — which in a storage system is called namespace — has to be distributed across the system to avoid bottlenecks.
In a petabyte scale system, backups are no longer meaningful, because it takes too much time to copy the bytes. Instead, there are multiple replicas, error correction codes, and striping. This means that there are multiple copies of everything and locking as well as failure recovery are very difficult to implement under the constraint not to reduce scalability while retaining strict coherence.
There are only few successful implementations of a distributed scalable file system. Examples include Isilon and Lustre. If we add the constraints of being hardware agnostic and support multi-level tiering with pathnames that do not change when a file is moved to a different tier, the Peaxy Hyperfiler might be the only distributed file system with truly no other bottleneck than the network bandwidth, especially in the case of many small files.
Category: Uncategorized






