Yes, Real-Time Streaming Data Is Still Growing
By Alex Woodie–A funny thing happened while the tech world was focused almost exclusively on ChatGPT over the past eight months: Adoption of other cutting-edge technologies kept growing. One of those is real-time stream data processing, interest in which has been quietly building over the past couple of years for several high-impact use cases.

IDC says the stream processing market is expected to grow at a compound annual growth rate (CAGR) of 21.5% from 2022 to 2028. “This growth is being driven by the increasing volume and velocity of data, the need for real-time analytics, and the rise of the Internet of Things (IoT),” the analyst group says.
Over at Databricks, 54% of its customers are using Spark Structured Streaming, according to Databricks CEO Ali Ghodsi.
“A lot of people are excited about generative AI, but they’re not paying attention to how much attention streaming applications actually now have,” Ghodsi said during his keynote two weeks at the Data + AI Summit. “It’s actually 177% growth in the past 12 months if you look at the number of streaming jobs.”
The past year has seen a number of enhancements in Spark Structured Streaming thanks to Project Lightspeed, which Databricks launched a year ago. The project is increasing processing times and dropping latency, Ghodsi said.
Companies like Columbia, AT&T, Walgreens, Honeywell, and Edmunds are using Spark Structured Streaming in production, according to a recent blog post on Project Lightspeed. The company runs an average of 10 million Structured Streaming Jobs per week on behalf of customers, which it says is growing at 2.5x per year. New enhancements as part of the project, such as microbatch pipelining, will help to improve Structured Streaming.
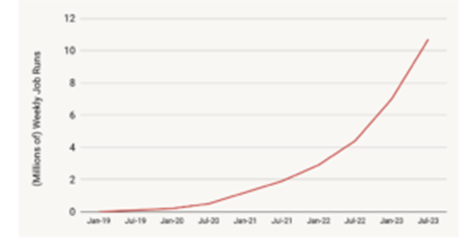
Spark Structured Streaming usage is growing fast, Databricks says
But Databricks isn’t the only vendor making progress with streaming data. Confluent continues to attract new users and introduce new features to its hosted streaming data platform, dubbed Confluent Cloud, which is based on the Apache Kafka message bus.
Nearly half (44%) of Confluent’s streaming data users say the technology is a top strategic priority, with 89% saying it’s important, according to Confluent’s 2023 Data Streaming Report. What’s more, the more experience customers get with streaming data, the higher their return on investment, Confluent says in the report.
In addition to the core Kafka message bus, Confluent sells stream processing systems that ride on the bus. And with its acquisition of an Apache Flink startup called Immerok late last year, Confluent hopes to give a boost to its revenues, which grew 38% last quarter.
Confluent and Databricks have lots of competition from smaller vendors, however. A startup called Redpanda recently raised $100 million to help it build a new distributed messaging framework that’s fully compatible with Apache Kafka. Redpanda’s offering is written in C++, which has certain advantages over the Java codebase that Kafka runs on. (Kafka, for its part, is finally moving away from Zookeeper, the Java-based, Hadoop-era framework underlying its distributed architecture).
Another stream processing vendor to keep an eye on is RisingWave Labs. The company, which builds a distributed SQL streaming database, recently launched a fully managed version of its product. Dubbed RisingWave Cloud, the offering eliminates the need for the customer to run and maintain the underlying streaming data infrastructure, freeing them to focus on building real-time applications using SQL.
You may also want to keep an eye on Nstream. Formerly known as Swim (click here to read our August 2022 profile), the company has built a stream processing product designed to maintain the state of events while simultaneously handling massive event volumes, something that has bedeviled stateless approaches, such as those employed by Kafka. Nstream developed its own vertically integrated stack based in part on the actor approach (similar to Akka) to minimize latency for large-scale stateful processing.
Nstream was one of the vendors mentioned in a recent Gartner report on the state of event stream processing platforms. The Market Guide for Event Stream Processing (ESP) notes that real-time data sources are proliferating, both from internal sources like corporate websites, sensors, machines, mobile devices and business applications; as well as from external sources, such as social media platforms, data brokers and business partners.
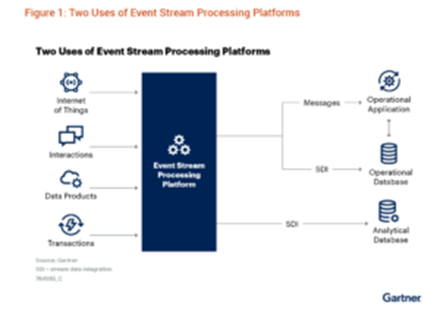
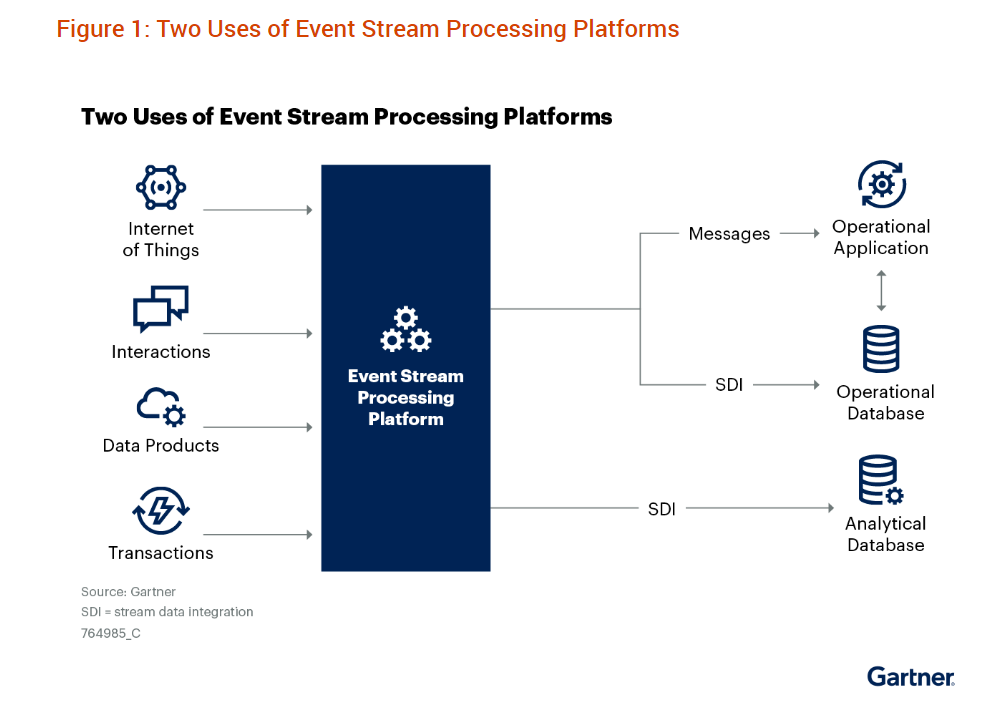
There are two types of ESP applications, Gartner says
“This information is most valuable when it is used as soon as it arrives to improve real-time or near-real-time business decisions,” Gartner analysts write. “ESP platforms are essential components in many new systems that provide continuous intelligence, enhanced situation awareness, and faster, more-precise business decisions.”
Gartner breaks the ESP market down into three categories, including pure open source, “open core” offerings, and proprietary ESP systems. Open-source offerings making Gartner’s Market Guide include those from Apache Software Foundation, which develops the Kafka Streams, Flink, Spark Streaming, Storm, and Heron offerings. Gartner says open source offerings are helping to drive down the cost of ESP deployments.
The open core category includes vendor-backed products based on open source code. Gartner lists several in its report, including (but not limited to):
- Aiven, which develops a stream processing service atop Apache Flink;
- Axual, which hosts an Apache Kafka-based real-time system;
- Cogility, which develops ESP atop Flink;
- Cloudera, which develops real-time systems using Apache Nifi and Flink;
- Gigaspaces, an in-memory data grid (IMDG) that has incorporated Flink;
- GridGain Systems, the IMDG developer behind Apache Ignite;
- EsperTech, which develops an in-memory processing engine for real-time data that runs on Java and .NET;
- Instaclustr (owned by NetApp), which develops an ESP platform atop Kafka and Apache Cassandra;
- Lightbend, which develops the Akka framework;
- Google Cloud, which develops the Cloud Dataflow engine.
And in the proprietary category, Gartner has:
- Hazelcast, which develops an open source, Java-based, in-memory data grid (IMDG) that can be used to build ESP systems;
- Hitachi, which develops the Hitachi Streaming Data Platform;
- Oracle, which developed the GoldenGate Stream Analytics product;
- Microsoft Azure, which develops the Azure Stream Analytics and StreamInsight offerings;
- SAP, which develops the Leonardo IoT and Edge Services products;
- SAS, which develops Event Stream Processing
- Software AG, which develops Apama Streaming Analytics;
- TIBCO Software, which develops Streaming and Cloud Integration.
Two-thirds of the ESP deployments Gartner sees support real-time operational systems. This includes applications that require quick decision-making based on fresh data reflecting real-time events. The other third of ESP deployments are used to ingest, transform, and store data for later analytics. In that respect, it’s basically a real-time version of traditional ETL and ELT processes.
Real-time data often arrives via the message bus, which is often Kafka (reportedly used by 80% of the Fortune 100), but data could also arrive via Apache Pulsar, RabbitMQ, Solace PubSub+, or TIBCO Software Messaging, the analysts note. The data is then routed to the ESP applications and frameworks, where data is processed or routed to object stores, distributed file systems, or databases for subsequent use.
Category: Uncategorized







{kind=link}
{kind=link}